Yahoo Cloud Object Store - Object Storage at Exabyte Scale

Yahoo stores more than 250 Billion objects and half an exabyte of perpetually durable user content such as photos, videos, email, and blog posts. Object storage at Yahoo is growing at 20-25% annually. The growth is primarily driven by mobile, images, video, and user growth. Yahoo is betting on software defined storage to scale storage cost effectively along with the durability and latency guarantees.
Object Storage Landscape at Yahoo
What is "object storage"? Images and photos in Flickr, Videos, and documents, spreadsheets, and presentations exchanged as Mail attachments are classic examples of "objects". The typical quality of this class of data is "write-once-read-many". Traditionally, Yahoo has used storage appliances for object storage. As Yahoo is increasingly becoming the guide for digital information to our users, object storage need in Yahoo is growing rapidly. Additionally, application characteristics differ in access patterns, durability and latency needs, and cost targets. To support growth cost effectively and meet the varying application needs, object storage in Yahoo requires different tradeoffs. We need the flexibility offered by software defined storage to deliver these tradeoffs.
Why Software Defined Storage
Key benefits of software defined storage are:
- Cost-performance tradeoff: Allows applications to choose performance and cost tradeoffs with different hardware and durability configurations using the same software stack.
- Flexible interfaces: Ability to choose industry standard API, embed client libraries in applications, or even use proprietary API where required. Industry standard APIs allow seamless migration of applications from public to Yahoo private cloud.
- Different storage abstractions: Leverage the same storage software stack across Object, Block, and File abstractions, thus reducing R&D and operational costs.
Cloud Object Store (COS) is Yahoo's commodity hardware based software defined storage solution. In partnership with Flickr Yahoo has completed a multi-petabyte initial deployment of COS. Yahoo plans COS as a multi-tenant hosted service and to grow COS by ten-fold to support Flickr, Yahoo Mail and Tumblr. That is 100s of petabytes of storage to be supported on COS.
Under the Hood
COS is deployed using Ceph storage technology. Yahoo evaluated open-source solutions such as Swift and Ceph, as well as commercial solutions and chose Ceph because it enables consolidation of storage tiers for Object, Block, and File with inherent architectural support. Also, being an open-source product, Ceph provides the flexibility needed to customize for Yahoo needs.
COS deployment consists of modular Ceph clusters with each Ceph cluster treated as a pod. Multiple such Ceph clusters deployed simultaneously form a COS supercluster as shown in figure below. Objects are uniformly distributed across all the clusters in a supercluster. A proprietary hashing mechanism is used to distribute objects. The hashing algorithm is implemented in a client library embedded in the applications.
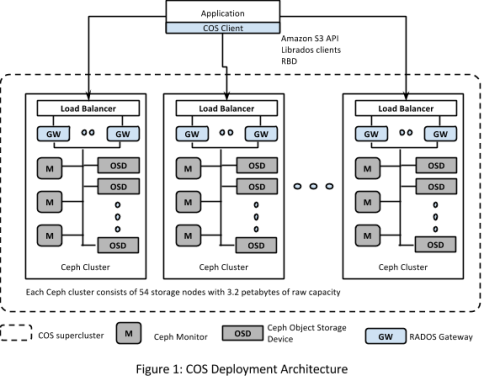
Since each cluster consists of tens of commodity servers and hundreds of disks, it is highly likely that components will fail frequently. High disk and network activity occurs during recovery due to rebalancing of objects, which in turn increases object read latency during this phase. Capping the size of each cluster allows Yahoo to limit the resource usage during recovery phases in order to adhere to latency SLAs.
Yahoo users expect their images, videos and mail attachments to be perpetually stored, and made available instantaneously from anywhere around the world. This requires high data “durability” guarantees. Durability is typically achieved in storage systems either via redundancy or encoding. Redundancy can be provided through extra copies of data or replicas. On the other hand, encoding can be provided via traditional mechanisms like simple parity, or more sophisticated mechanisms like erasure coding. Erasure coding breaks down an object into fragments and stores them across multiple disks with a few redundant pieces to tolerate multiple failures.
The usable capacity of each cluster depends on the durability technique used. We currently employ erasure coding with each object broken down into eight data and three coding fragments. This mechanism, called 8/3 erasure coding, can tolerate up to three simultaneous server and/or disk failures with about 30% storage overhead for durability. This is much lower than the 200% overhead in case of replication.
The two durability techniques offer different price points and latency characteristics. Replication offers lower latency but a higher cost, whereas erasure coding reduces cost (sometimes by up to 50%) at a slightly higher latency. We can also deploy different storage media such as SSD, HDD and Shingled Magnetic Recording (SMR) drives to enable different service levels depending on the application.
Technically, it is possible to scale a COS supercluster by adding storage needs to increase the capacity of the component clusters. However, this will lead to rebalancing of data within the component clusters, thereby creating prolonged disk and network activity and impact latency SLA. To scale COS, our preferred approach is to add COS superclusters as needed similar to adding storage farms. This approach is consistent with our current appliance-based storage solution that applications are already familiar with.
Latency Optimizations
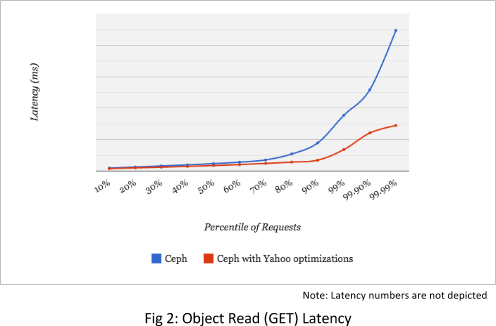
COS is in the serving path for many Yahoo applications and has to guarantee latency SLAs to ensure consistent high quality of user experience. We have implemented over 40 optimizations in Ceph to realize 50% improvement on average, and 70% improvement in 99.99% latency. The figure below depicts the latency chart before and after the optimizations under normal operations. The latencies in this chart are measured across objects of different sizes in the Flickr workload.
Some of the major optimizations are:
- Redundant parallel reads with erasure coding: Currently, we have deployed 8/3 erasure coding scheme for durability. Increasing the parallel reads to 11 chunks, instead of the default 8 employed in Ceph, and reconstructing the object upon first 8 retrievals provided significant improvement in long tail read latency. This reduced average latency by approximately 40%.
- Recovery Throttling: Upon disk and node failures, Ceph automatically initiates recovery to maintain high durability of objects. During recovery, storage nodes are busy leading to high read/write latency. We implemented tunable recovery throttle rate to mitigate this impact. This reduce average latency during recovery by approximately 60%.
- Bucket Sharding: Amazon S3 API specification requires objects to be bucketized. Ceph implements bucket as an object hosted on a single storage node. At our scale, the storage node that hosts the bucket becomes a hotspot, which we mitigated by implementing sharded buckets that are spread across multiple nodes.
Future Development
So far, Yahoo has tuned COS to a large Yahoo use-case, namely Flickr. However, other Yahoo use cases require object storage with different workload patterns and different tradeoffs. To make COS a widely used platform at Yahoo, several enhancements in near to mid-term are
- Scale: Yahoo has already deployed an initial multi-petabyte solution planned to grow this 10-fold or more to accommodate other use cases such as Mail, Video, Tumblr etc. along with Flickr growth.
- Geo Replication for Business Continuity: Currently, geo replication is carried out at the application level. Ceph supports Geo-replication. However, Yahoo has not tested this capability for the scale and latency that Yahoo needs and planned to scale and deploy geo-replication in COS.
- Optimize latency for small objects: Many use-cases such as serving thumbnails and serving during image search have small objects of the order of a few kilobytes. COS needs to be tunned for these use-cases.
- Lifecycle management: One of the big advantages of Software Defined Storage is the hardware, software choices for cost and performance tradeoffs. Automatic classification of objects into hot, warm, and cold objects will allow us to take advantage of that flexibility and provide differentiated services.